Errores de diseño más comunes en bases de datos relacionales
El diseño de una base de datos es una etapa crítica que influye directamente en el rendimiento, escalabilidad y seguridad de cualquier sistema. Sin embargo, en muchos proyectos ya sea por desconocimiento, presión de tiempo o falta de planificación se cometen errores comunes que pueden traer consecuencias costosas a largo plazo. En este artículo haremos un recorrido por algunas de las malas prácticas más frecuentes en el diseño de bases de datos que me he encontrado a lo largo de mi experiencia, independientemente del motor utilizado.
Falta de historización
La falta de historización es la ausencia de mecanismos para registrar cambios a lo largo del tiempo en resumidas palabras es cuando el cambio de un dato hace que la información anterior a ese cambio sea incorrecta.
Para entender mejor este problema y el resto de errores que veremos en este articulo usaremos el siguiente ejemplo: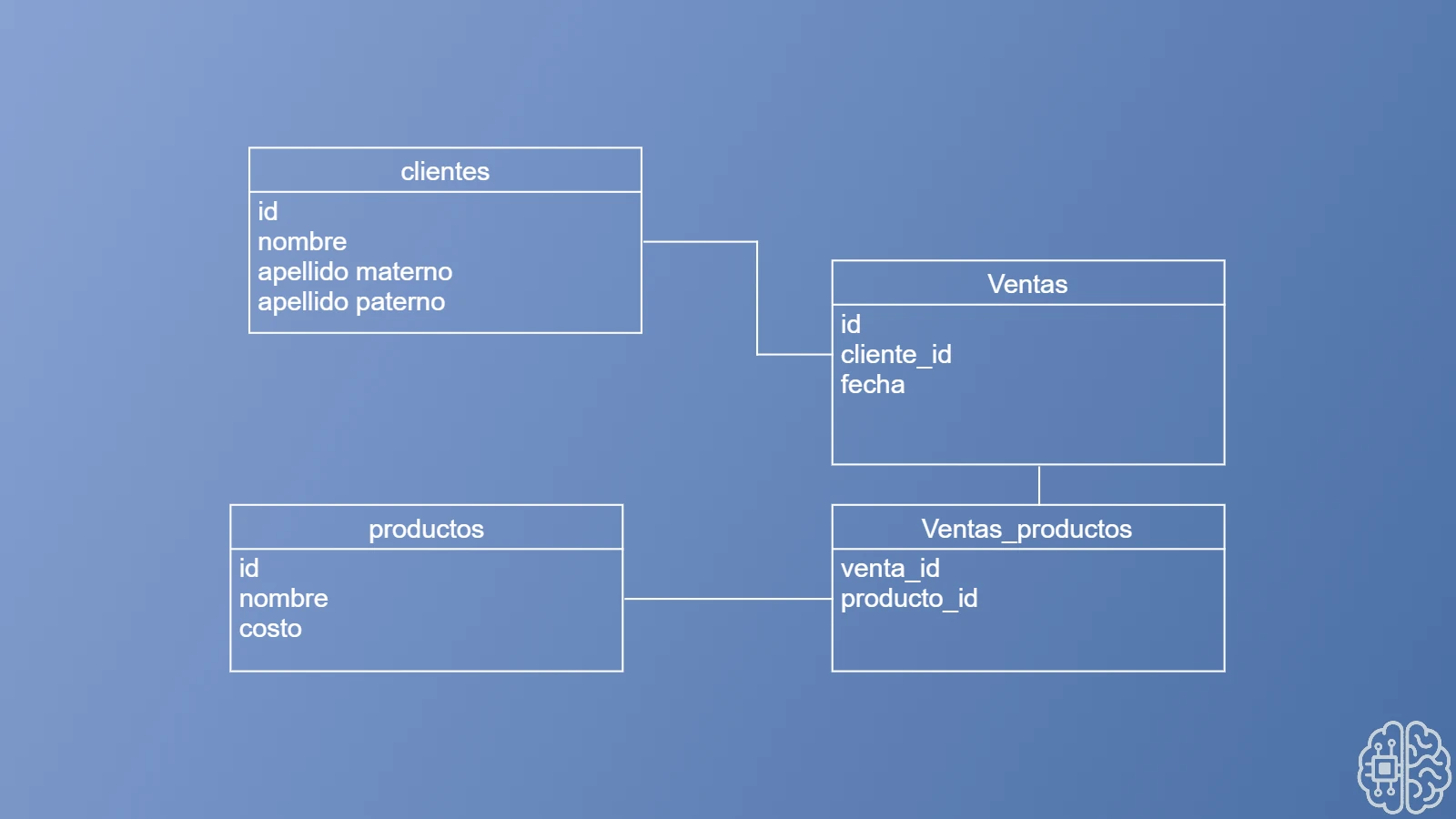
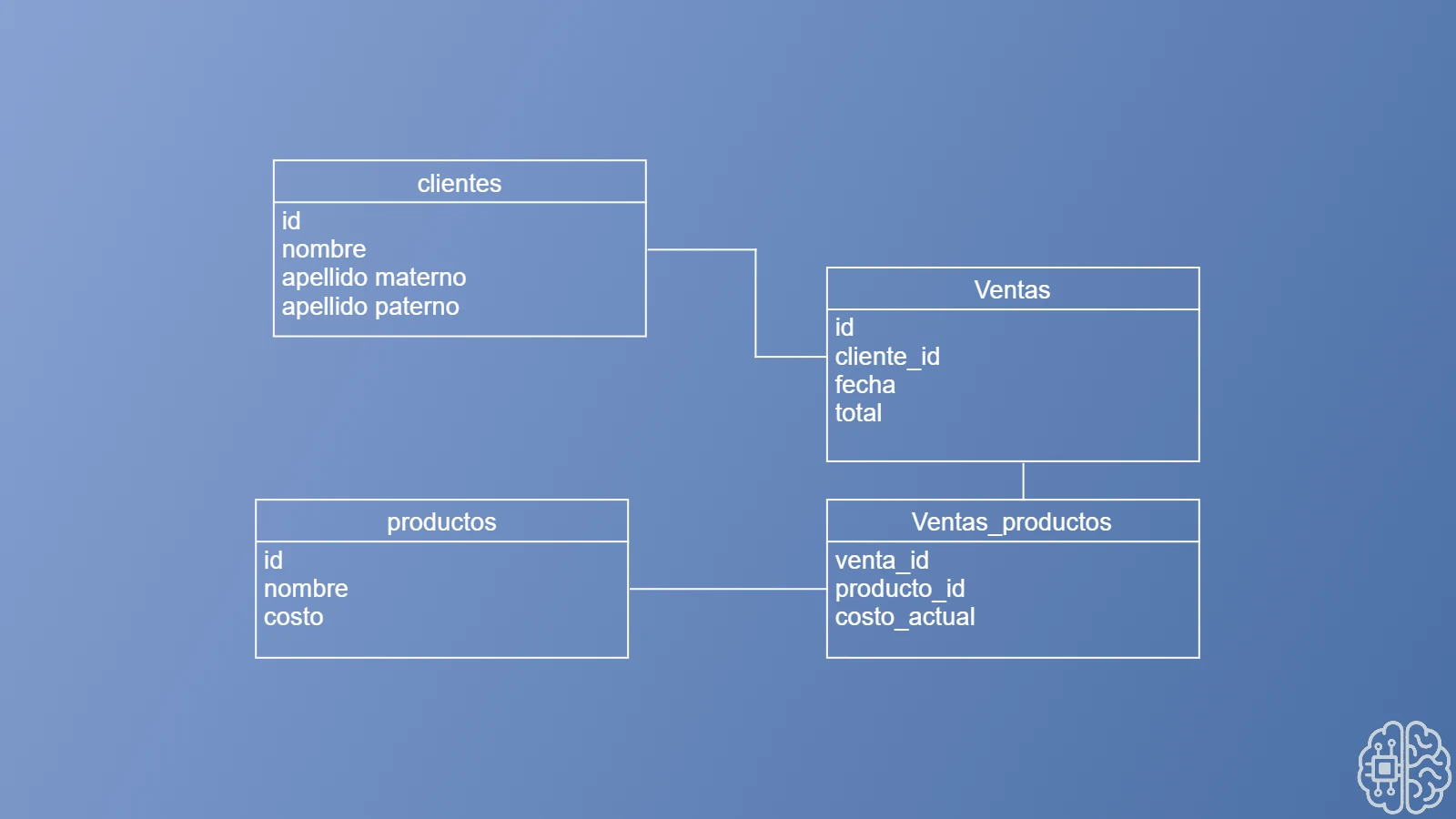
Como podemos observar en este modelo de datos, tenemos cuatro tablas: clientes, ventas, productos y venta_productos. Un cliente puede realizar muchas ventas, y una venta puede estar compuesta por varios productos.
A simple vista, parece que no hay nada malo con el diseño, pero ¿qué pasa si cambiamos el costo de un producto? ¿Lo ves? Estamos perdiendo datos al momento de realizar el cambio de costo en un producto que ya ha sido vendido. Todas las ventas anteriores dejan de tener sentido, ya que el costo que se mostrará será el nuevo, y no el que tenía al momento en que se efectuó la venta.
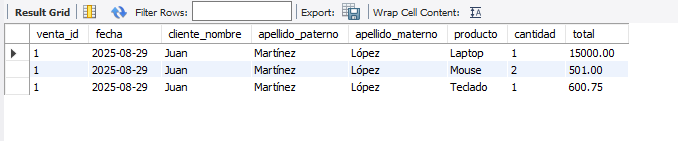
Para entenderlo mejor imaginemos que realizamos una venta con tres productos una Laptop, un mouse, teclado:
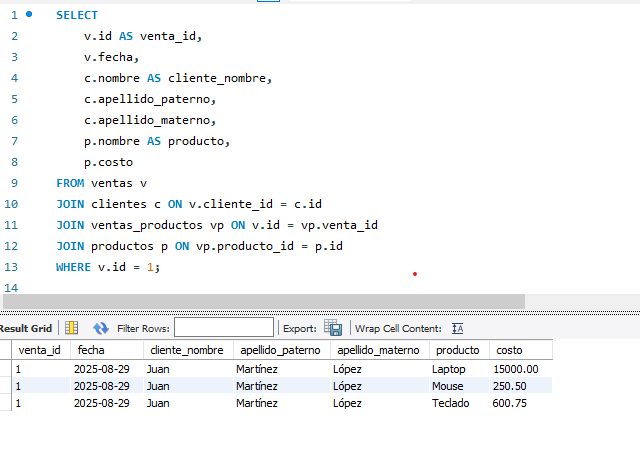
Ahora supongamos que el precio del mouse cambia pasa de 250.50 a 300.00.
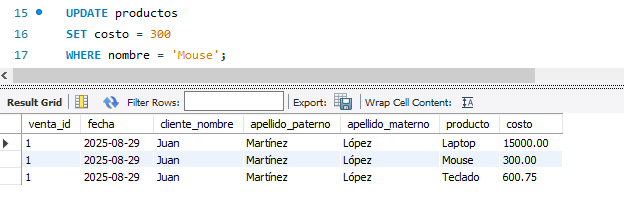
Como podemos ver el coste del Mouse cambio pero el coste en el que se vendió originalmente no fue de 300.00 si no de 250.50.
Esto sucede porque el campo costo de la tabla productos es un dato que cambia constantemente, ya sea por inflación, demanda, promociones, etc. Es decir, es un dato altamente variable en el tiempo.
La solución es relativamente sencilla: basta con añadir un campo a la tabla pivote venta_productos. En este caso, se optó por añadir el campo costo_actual, para indicar el costo del producto en el momento en que se realizó la venta. De esta manera, evitamos la pérdida de información histórica.
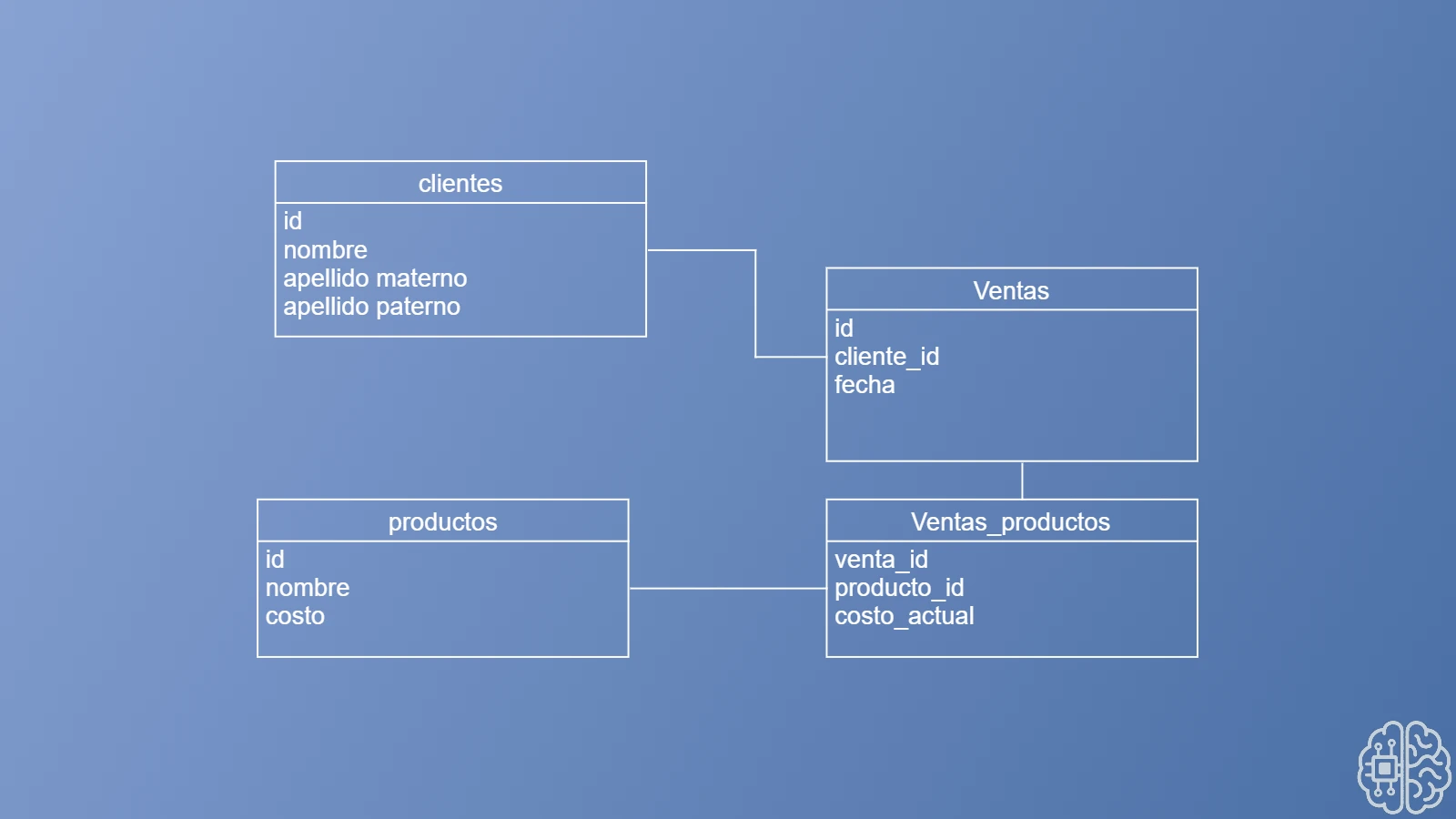
Este simple añadido ahora nos permite realizar cambios en el costo del producto sin afectar el historial de datos, tal como se puede observar en la siguiente imagen:
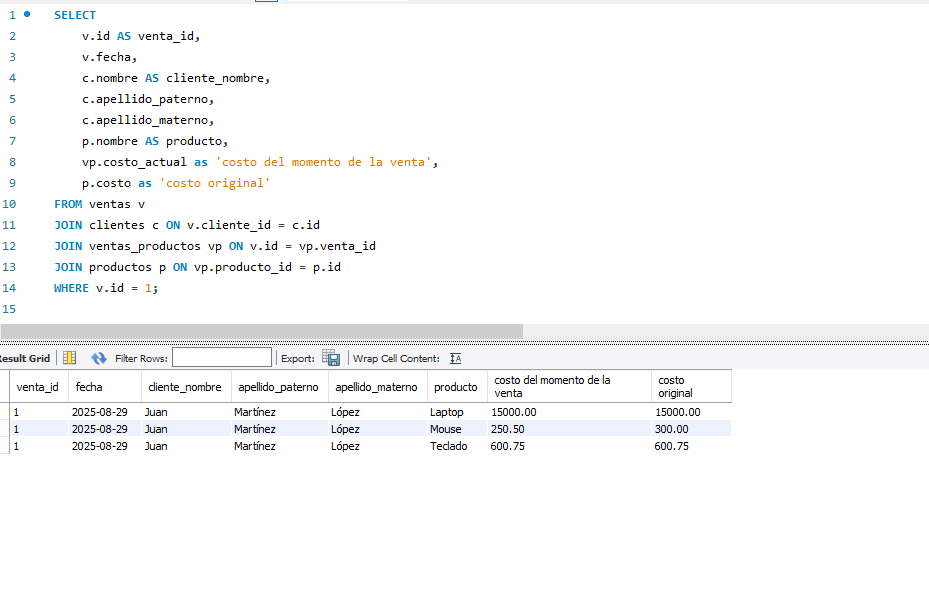
con este sencillo cambio ya podemos editar el costo sin afectar el histórico es decir el momento en que se realizo la venta dado que el coste original y el coste en el momento en que se realizo la venta ya están almacenados en campos independientes.
Ausencia de redundancia controlada
Cuando nos estamos introduciendo al mundo de las bases de datos relacionales, nos enseñan que uno de los objetivos principales es eliminar la redundancia, y efectivamente, esa es una de las razones clave. Sin embargo, hay ocasiones en las que la mejor opción es introducir cierta redundancia en la base de datos.
Lo sé, puede sonar contradictorio. Déjame explicártelo.
Verás, cuando las bases de datos comienzan a crecer, consultar datos entre millones de registros puede volverse lento y costoso a nivel computacional. Es en estas situaciones donde añadir campos redundantes puede ser una mejor solución. En particular, se pueden almacenar datos estáticos es decir datos que no cambian con el tiempo. y por ende su redundancia evita la necesidad de realizar relaciones complejas entre tablas cada vez que se desea consultarlos.
Esta técnica no solo aplica a datos estáticos, también puede ser útil para almacenar resultados de operaciones complejas o costosas en tiempo de cálculo.
Todo esto se conoce como desnormalización (o también como denormalización sin “s”), es una técnica de diseño que consiste en añadir redundancia de forma intencional para mejorar el rendimiento de una base de datos.
Para entenderlo mejor, retomemos el ejemplo anterior. Actualmente, para obtener el total de una venta, es decir, la suma del costo_actual de todos los productos involucrados en esa venta, debemos realizar la operación cada vez que consultamos los datos. Esto puede ser complejo y lento.
En cambio, si añadimos un campo llamado total a la tabla de ventas, esta operación ya no será necesaria, ya que el valor ha sido previamente calculado y almacenado. Esto facilita considerablemente las consultas y mejora su rendimiento.
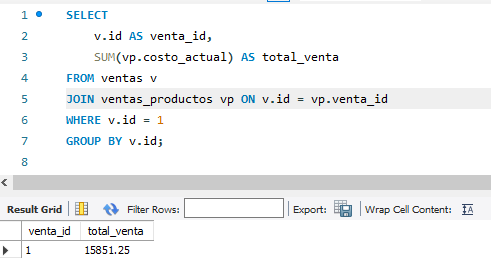
En el ejemplo anterior es una forma en la que nosotros obtenemos el total de una venta que se realizo. Como podemos observar en la imagen, tenemos que hacer uso de SUM y de un JOIN, pero si añadimos el campo total a la tabla de ventas basta con utilizar el atributo total para obtener el valor de la venta, sin necesidad de hacer sumas en tiempo real. Con este cambio, nuestro modelo de datos quedaría así:
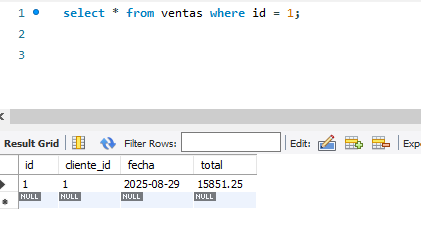
Y para consultar el total podríamos hacerlo directamente desde la tabla de ventas ya que el campo fue previamente calculado sin necesidad de hacer un JOIN a la tabla de ventas_productos:
Falta de soporte para auditorias
Para empezar, ¿qué es una auditoría?
Una auditoría no es más que la capacidad de registrar quién, cómo y cuándo se realizó una acción dentro de un sistema. Este tipo de control es fundamental para:
- Detectar fraudes
- Rastrear cambios maliciosos o accidentales
- Contar con evidencia ante cualquier modificación
- Mantener un historial claro de actividad
Volviendo al ejemplo de nuestro modelo de datos, para permitir auditorías hemos añadido el campo creado_por en la tabla de ventas, lo que nos permite saber quién realizó una venta y cuándo lo hizo.
Además, en las tablas de productos y clientes se han añadido los siguientes campos:
- creado_por: quién creó el registro
- creado_el: fecha y hora de creación
- ultima_actualización_por: quién fue el último en modificar el registro
- ultima_actualización_el: fecha y hora de la última actualización
Con estos campos, nuestro sistema ahora es capaz de mantener un historial claro y completo sobre los cambios realizados, lo que mejora la transparencia y permite realizar auditorías de forma efectiva.
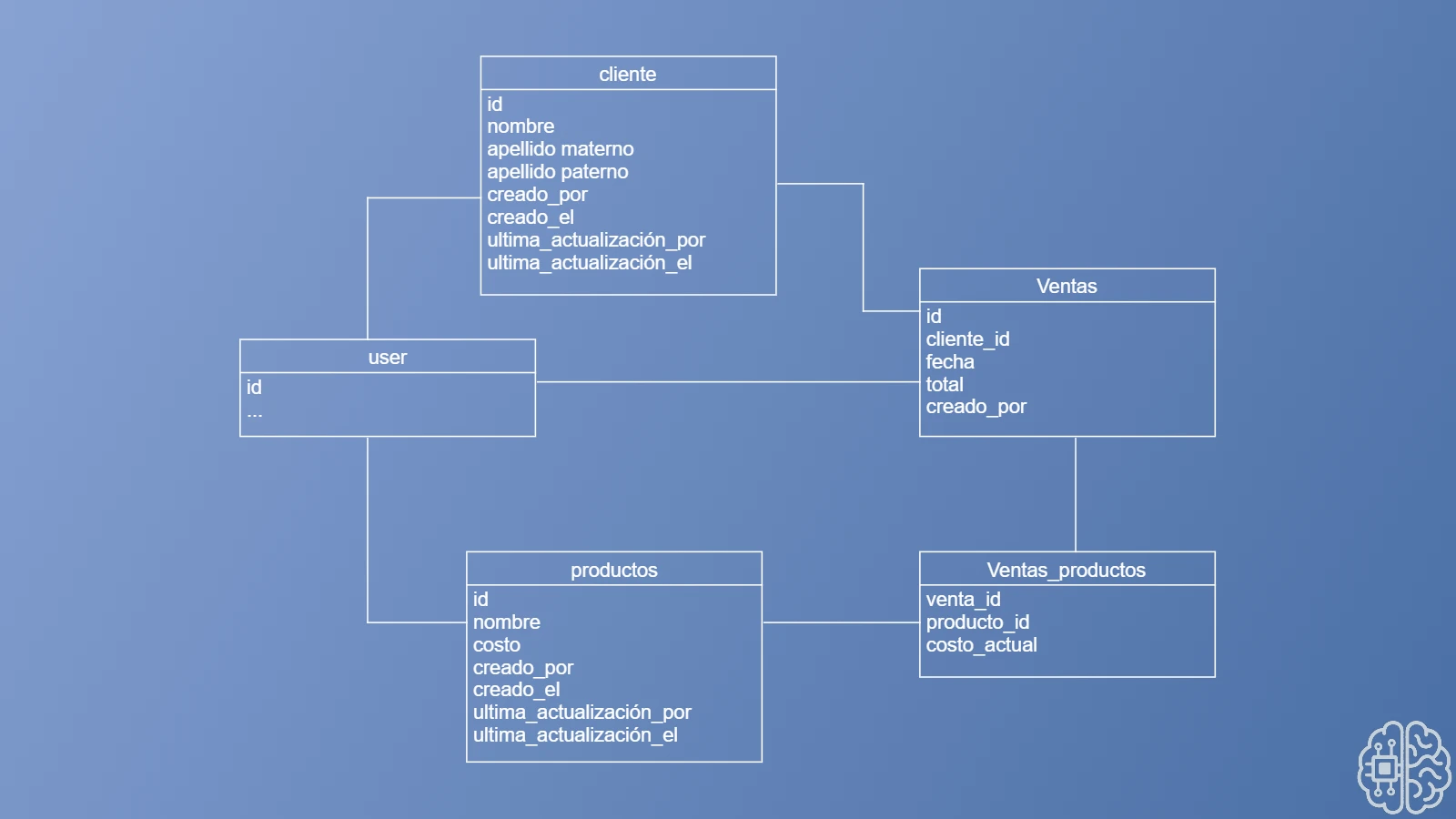
Como podemos observar, nuestro modelo de datos solo toma en cuenta la fecha de creación, la última actualización y qué usuarios realizaron estas acciones. Sin embargo, esto deja abierta la posibilidad de que ocurran otras actualizaciones entre el momento de creación y la última modificación que no queden registradas.
El ejemplo que mostré es solo una de las muchas formas de implementar auditoría en las tablas. Existen otras opciones, como:
- Crear una tabla exclusiva para el historial de cambios
- Guardar los cambios en un campo adicional usando un formato como JSON
- Utilizar triggers para capturar automáticamente las modificaciones
Al final, el límite lo marcan el tiempo, los recursos y los requerimientos específicos de tu proyecto.
Modelo de datos no optimizado para operaciones reales
Y por último, está el problema de no optimizar la base de datos para operaciones reales. ¿A qué me refiero con esto? Bien, nuestro modelo hasta este punto puede ser completamente funcional, pero ¿qué ocurre si queremos comprar dos mouse en una sola venta?
Técnicamente es posible, pero para lograrlo tendríamos que crear dos registros separados (o más, si se desean más unidades del mismo producto). Este enfoque es ineficiente y refleja un modelo de datos no optimizado para operaciones reales. Es decir, se trata de un modelo que no está diseñado de forma adecuada para manejar operaciones comunes, como en este caso, la compra de múltiples unidades de un mismo producto dentro de una sola transacción.
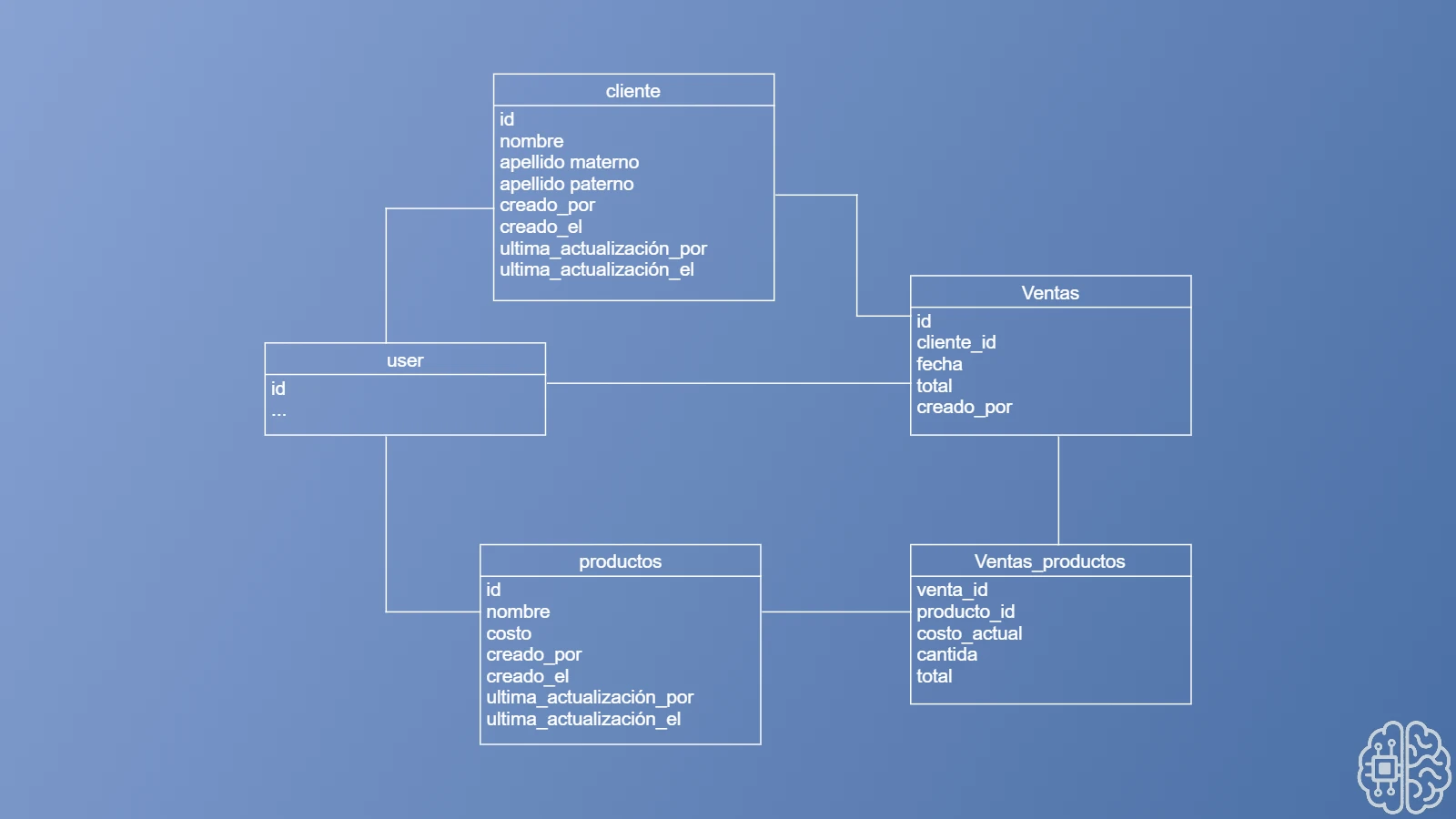
¿Cómo resolvemos esto? simple añadiendo un campo de cantidad en ventas productos (también podemos añadir el campo total para no tener que calcularlo de nuevo como lo vimos anteriormente).
nuestro modelo quedaría así:
Esto ha sido todo.
Espero que este artículo te haya sido útil. Sé que muchas cosas pueden parecer obvias ahora, pero es importante recordar que la base de datos es uno de los componentes más importantes de un sistema. Cualquier error que pase desapercibido y llegue a producción será más costoso y difícil de corregir.
Por eso, una buena planificación desde el principio y seguir buenas prácticas en el diseño de bases de datos ayudará a reducir la deuda técnica en el futuro.
Comentarios